LLM price performance comparison: Why intelligence-to-cost ratio defines enterprise AI success
02 Jun 2025
02 Jun 2025
The artificial intelligence landscape is constantly evolving as new models redefine what’s possible at increasingly competitive price points. Every business knows data must work harder, and future success demands the deployment of sophisticated LLMs. But to do this at enterprise level, it is absolutely vital to undertake an LLM price performance comparison to identify solutions that balance capabilities with economic viability.
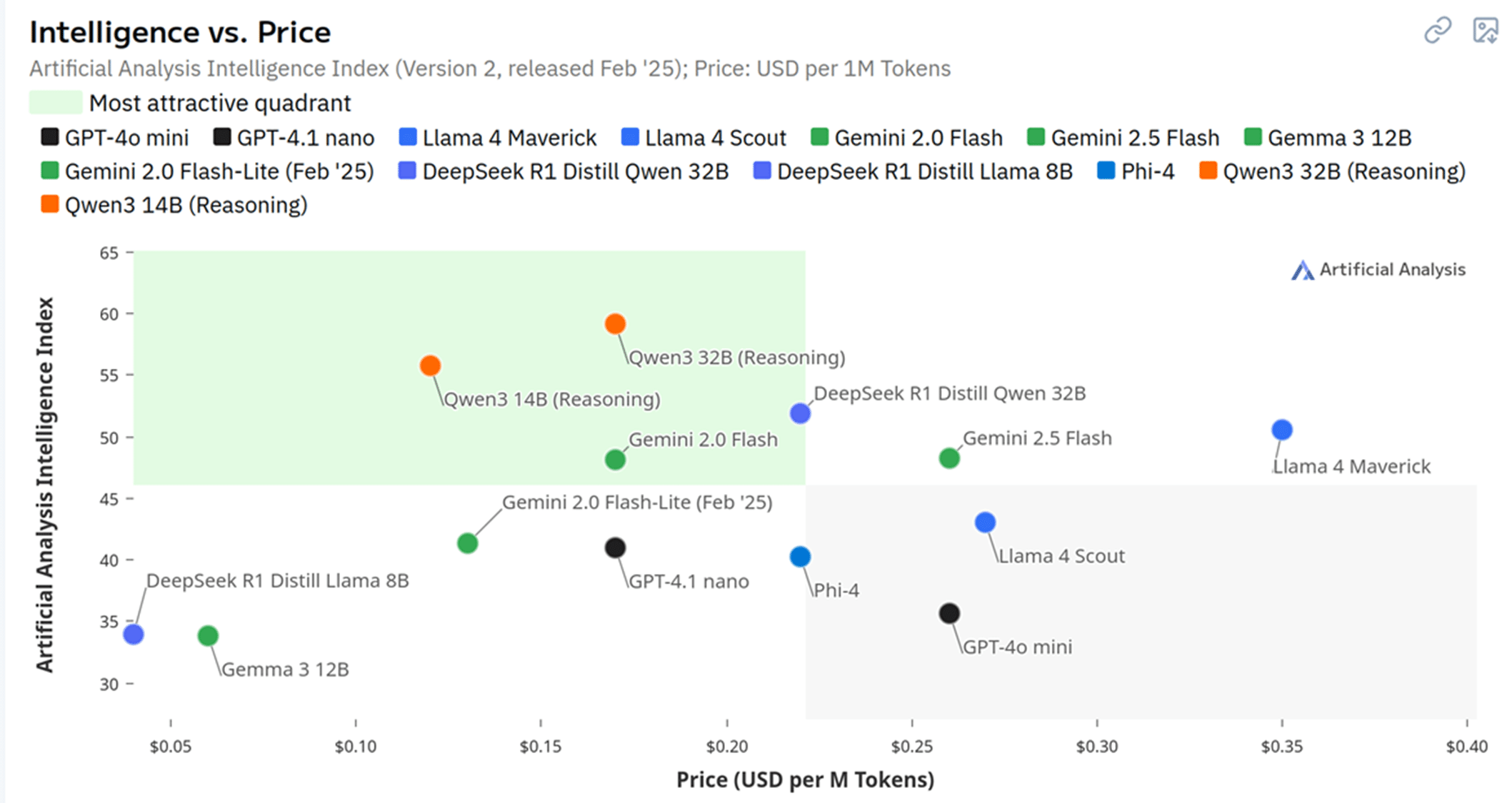
Here, the recent findings from the Artificial Analysis Intelligence Index (Version 2, released February ’25) offer valuable insights into how enterprise AI strategies should evolve. In this commentary, we’ll share our thoughts on these LLM price performance comparison findings and what they mean for practical AI implementation.
From our perspective working with institutional clients across financial services and energy trading, this positioning reflects a broader shift in how AI systems are being optimised for practical implementation. Though it’s important to note that such raw intelligence scores from LLM price performance comparison studies rarely translate directly to business value when taken in isolation.
What we think makes the Intelligence Index particularly valuable though is how it highlights that the most attractive quadrant in any LLM price performance comparison isn’t necessarily the highest absolute intelligence, but rather the optimal balance between capability and cost. This aligns perfectly with what we’ve seen in our own deployment patterns – whilst we initially tested multiple high-end models, our production systems now leverage a carefully calibrated mix that prioritises efficiency based on rigorous LLM price performance comparison analysis.
The Intelligence Index findings become even more interesting when viewed through the lens of practical implementation. Our experience implementing reasoning models for sentiment analysis has revealed nuances not captured in the standard LLM price performance comparison benchmarks presented in the report.
When we evaluate models like DeepSeek R1 Distill Qwen 32B versus Qwen3 32B Reasoning (both featured in the Intelligence Index), we look beyond their chart positioning to assess domain-specific capabilities. The practical implementation challenges we’ve encountered further complicate model selection beyond what any LLM price performance comparison study can fully capture.
Deployment factors like inference latency and token context length often matter more than the raw benchmark scores highlighted in LLM price performance comparison reports. This is particularly true given the specific demands of financial market analysis, where timely insights outweigh marginal improvements in reasoning quality.
This is why we’ve developed an internal evaluation framework that extends beyond the Intelligence Index findings to include domain-specific performance metrics. Rather than relying solely on the generic intelligence scores from LLM price performance comparison studies such as these, we measure how effectively each model captures market sentiment shifts across financial narratives.
The intelligence-price matrix presented in the Artificial Analysis Intelligence Index offers valuable guidance, but our most important insight comes from understanding how these models behave in specific business contexts. Based on the LLM price performance comparison analysis of the Index findings, reasoning-optimised models like Qwen3 32B and 14B (Reasoning) deliver disproportionate value for financial applications.
One observation from the Intelligence Index data is that assuming higher-scoring models automatically deliver better business outcomes would be misguided. Our own LLM price performance comparison testing revealed that in some financial analysis tasks, strategically fine-tuned smaller models outperformed larger generic ones despite their lower positioning in the Index benchmarks.
The Intelligence Index findings suggest that most important decisions around model selection require nuanced understanding beyond published LLM price performance comparison metrics. Here a Permutable, what makes our approach distinctive is how we continuously evaluate model performance across financial analysis tasks rather than relying exclusively on the Intelligence Index scores.
The rapid emergence of models in the top-left quadrant (high intelligence, lower price) identified by the Intelligence Index signals what we believe is a market shift toward democratised AI capabilities. The exceptional intelligence once reserved for the most expensive models is now available at more accessible price points, creating opportunities for wider enterprise adoption based on improved LLM price performance comparison ratios.
Our production systems incorporate multiple models from the high-value quadrant identified in the Intelligence Index LLM price performance comparison analysis, carefully selected based on domain-specific performance for different aspects of financial analysis. The Index data supports our model composition strategy – effectively combining multiple specialist models rather than relying on a single general-purpose solution.
This reflects what we’re seeing across sophisticated AI implementations – the building of model portfolios based on comprehensive LLM price performance comparison analysis rather than betting everything on a single solution highlighted in benchmark studies like the Intelligence Index.
However, we’ve noted an important pattern that the Intelligence Index doesn’t fully capture: models that excel at financial sentiment analysis often differ from those that perform best on general benchmarks. The skills required for market prediction can differ substantially from those needed for summarisation, highlighting the importance of task-specific LLM price performance comparison beyond what standard indices reveal.
Against this backdrop, we continue to refine our evaluation methodologies to better align with real-world financial use cases, building upon the foundation provided by studies like the Intelligence Index. While GPT-4o mini shows relatively lower benchmark performance in the LLM price performance comparison data, for certain narrow financial tasks, it provides excellent value given its competitive positioning.
Are you looking to realise a particular enterprise AI project within the financial services sector? At Permutable, we work with select partners on enterprise AI transformation projects, bringing our proven expertise in interpreting LLM price performance comparison data and implementing practical solutions. As markets grow increasingly complex, the right AI strategy has now become a powerful competitive advantage. We collaborate with forward-thinking organisations to implement sophisticated, domain-specific AI solutions that deliver measurable business value and outcomes.
Contact us at enquiries@permutable.ai to arrange an initial discussion about your AI transformation goals and explore how our intelligence-driven approach can support your strategic objectives.

Analysis
22 Jul 2026
UK inflation fell to 2.6% after Permutable’s Global Macro Sentiment Indices saw it coming
Read more >
Analysis
21 Jul 2026
China growth: Q2 GDP lays bare the limits of industry-led expansion
Read more >
Analysis
15 Jul 2026
The Price of Passage: How Geopolitical Sentiment Led the Repricing of Gulf Crude-Flow Risk
Read more >