
How to evaluate market intelligence APIs in 2026
14 May 2026
14 May 2026
This guide explains how institutional teams should evaluate market intelligence APIs in 2026, focusing on signal integrity, source traceability, point-in-time consistency, latency, historical replay, explainability and integration quality. It is aimed at systematic funds, macro teams, commodity desks, data engineers, risk teams and compliance stakeholders assessing intelligence APIs for research and production workflows.
For systematic macro, commodities and multi-asset teams, the challenge is no longer collecting more information. The challenge is determining which information is reliable enough to enter research, monitoring and production workflows.
Markets are increasingly shaped by fast-moving narratives: central bank language, geopolitical developments, supply disruptions, fiscal policy shifts, trade restrictions, weather events and changing demand signals. These events rarely move in isolation. An oil supply disruption can affect inflation expectations, FX pricing, rates, sovereign risk and industrial equities. A policy comment in one jurisdiction can reprice commodities, currencies and regional risk sentiment.
Traditional news feeds help teams see what has happened. Market intelligence APIs need to go further. They must convert unstructured global information into structured, timestamped and explainable signals that can be tested, monitored and integrated into institutional workflows.
The evaluation question is therefore not simply: does this API contain useful data?
It is: can this API produce signals that are traceable, consistent, explainable and robust enough to support investment decisions?
The first question should always be: what exactly is the API producing?
A market intelligence API may provide headlines, classifications, sentiment scores, event labels, entity tags, asset-level signals, narrative clusters, forecasts or alerting outputs. These are not equivalent. A document-level sentiment score is very different from a source-linked signal that explains which entity, asset, country or theme is being affected, when the signal changed and what evidence caused the move.
Institutional teams should evaluate:
A signal that cannot be explained is difficult to defend. A signal that cannot be reconstructed is difficult to backtest. A signal that cannot be traced is difficult to approve. For institutional adoption, signal integrity is the foundation.
Source traceability is one of the clearest differences between a research-grade API and a generic data product.
Institutional users need to know where a signal came from. That means the API should allow users to trace outputs back to the underlying source material, publication timestamp, entity mapping and classification logic.
This matters for three reasons.
A strong vendor should be able to answer:
If the answer is unclear, the signal is unlikely to pass institutional scrutiny.
Point-in-time consistency is essential for any team using market intelligence data in backtesting, research or systematic strategy development.
Many historical datasets look clean because they have been revised, corrected, enriched or backfilled after the fact. That may be useful for some forms of historical analysis, but it can create misleading backtests if the data does not reflect what would have been known at the time.
The key question is: can the API reconstruct the signal exactly as it appeared live?
Teams should test whether historical outputs preserve:
A credible provider should be able to explain how it prevents lookahead bias. It should also be able to show how historical replay differs from cleaned retrospective analysis. For systematic teams, this is not a technical detail. It is the difference between a signal that backtests well and a signal that can survive live deployment.
Latency matters, but should be defined precisely.
Not every macro or commodity workflow requires the same speed. A high-frequency execution strategy has different requirements from a daily macro allocation model, an intraday risk monitor, or a research workflow looking for early narrative shifts.
Institutional teams should define latency across four layers:
This distinction is important because a vendor may advertise “real-time” delivery while still having meaningful delays in ingestion, processing or downstream availability.
For systematic macro and commodities workflows, low-latency detection can be critical when signals feed intraday monitoring, risk dashboards or execution-adjacent models. For longer-horizon strategies, consistency, explainability and coverage may matter more than raw speed.
The right question is not just: is the API fast? It is: is the API fast enough, stable enough and transparent enough for the workflow it supports?
APIs often perform well under normal conditions. Institutional teams should focus on how they perform during market stress.
Stress periods reveal whether an API can maintain stable delivery when source volumes rise, narratives fragment and markets move quickly. This is particularly important around central bank announcements, geopolitical shocks, commodity disruptions, elections, sanctions, weather events and major macro data releases.
During evaluation, ask vendors to provide evidence of platform behaviour during specific market events. Then test the API using realistic workloads.
Important questions include:
A production-grade API should not only work when markets are quiet. It should remain stable when the signal matters most.
Backtesting compatibility should be tested early, not after commercial terms are agreed. A market intelligence API may have strong live capabilities but weak historical reconstruction. This creates problems for quant teams that need to evaluate signal behaviour over multiple regimes.
Strong historical replay should allow users to:
The evaluation should include known market episodes. For commodities, this may include supply disruptions, sanctions, OPEC decisions, LNG outages, weather shocks or inventory surprises. For macro, it may include inflation turning points, central bank pivots, fiscal events, sovereign stress or FX intervention episodes.
The goal is not simply to find a strong backtest. The goal is to determine whether the signal construction process is robust, explainable and repeatable.
Market events rarely stay within one asset class. A commodity disruption may affect inflation, rates and FX. A central bank communication shift may affect currencies, sovereign bonds, equity sectors and commodity demand expectations. A geopolitical escalation may influence energy, defence, shipping, insurance and risk sentiment.
This is why cross-asset intelligence matters.
Institutional teams should evaluate whether the API can model relationships between:
A basic sentiment API may classify a headline as positive or negative. A more useful market intelligence API should help identify how that event propagates across markets.
The strongest systems are not simply scoring text. They are structuring market-relevant relationships.
Sentiment is useful, but it is not enough. A positive or negative score can obscure the more important question: what is the market narrative and why is it changing?
For example, inflation sentiment may rise because of wage pressure, food prices, energy costs, currency weakness, fiscal expansion or tariff risk. Each driver has different market implications. A single aggregate score may miss that distinction.
Institutional users should assess whether the API can distinguish between:
This is especially important in macro and commodities, where causality often matters more than tone. The objective is not to know whether news is “positive” or “negative.” The objective is to understand what the market is beginning to price.
LLM-powered intelligence platforms should be evaluated carefully. Large language models can improve classification, entity resolution and narrative understanding. They can also introduce risks around hallucination, instability, opacity and domain mismatch.
Institutional buyers should ask:
The most credible LLM-powered platforms are not black boxes. They combine domain-specific modelling with source evidence, validation controls and auditability. For institutional workflows, explainability is not optional. It is part of the product.
A strong signal is only useful if it can be integrated cleanly. Data engineering teams should evaluate the practical implementation burden before committing to a vendor. Poor documentation, unstable schemas or unclear authentication can slow deployment and create ongoing maintenance risk.
Key integration criteria include:
The best APIs are easy to test, easy to monitor and easy to operationalise. A vendor should be able to support both research teams and production engineering teams. If integration depends on bespoke support for basic use cases, that is a warning sign.
Market intelligence APIs increasingly sit inside regulated investment workflows. That means evaluation should not be left only to research teams. Risk, compliance, information security and data governance teams should be involved early, especially where AI-generated outputs may influence investment decisions.
Important governance criteria include:
Regulatory expectations around AI are moving toward greater transparency and accountability. Vendors that cannot explain their governance model will become harder to approve over time.
A disciplined evaluation process reduces the risk of selecting a data product that looks impressive in a demo but fails in production. A useful process has four stages.
The goal is not to pick the most impressive demo. The goal is to select the API that can survive institutional use.
At Permutable, our Intelligence Engine and API is built for institutional teams that need explainable market intelligence across macro, commodities, FX and geopolitical risk. The platform converts global news and information flows into structured, source-traceable signals designed for research, monitoring and production workflows.
Our approach is built around five principles.
Signals can be traced back to underlying source material, helping teams understand what changed, when it changed and which evidence drove the move.
Historical outputs are designed to support point-in-time analysis, reducing the risk of lookahead bias in research and backtesting.
Permutable goes beyond isolated headline sentiment by tracking how market narratives evolve across countries, commodities, assets and macro themes.
The platform is designed to help teams understand how events propagate across markets, from energy and commodities to inflation, FX, rates and broader risk sentiment.
Permutable supports institutional delivery through API, data feed and workflow integration options, helping teams move from evaluation to deployment with a clear technical path.
A credible market intelligence API is not defined by the size of its dataset or the sophistication of its interface. It is defined by whether institutional teams can trust the signal.
That means the signal must be traceable, timestamped, explainable, historically replayable and stable enough for production use. It must support research workflows without introducing lookahead bias. It must integrate cleanly into existing infrastructure. It must withstand scrutiny from portfolio managers, quantitative researchers, risk teams, compliance teams and data engineers.
In 2026, the strongest market intelligence APIs will be those that help investment teams move from fragmented information to structured understanding. Not more noise – better signals.
A market intelligence API delivers structured data about market-relevant events, entities, narratives or signals. It allows investment teams to integrate external intelligence directly into research, monitoring, risk and production workflows.
An LLM-powered market intelligence API uses language models to classify, structure and interpret unstructured text. The strongest platforms combine LLM capability with source traceability, domain-specific validation and clear audit controls.
Point-in-time data allows users to reconstruct what was known at a specific moment. This is essential for backtesting because revised or backfilled data can create misleading results that would not have been achievable in live conditions.
Latency should be tested across the full chain: source publication, ingestion, classification, API availability and response delivery. Teams should test normal periods and market stress periods rather than relying only on headline latency claims.
Sentiment measures tone or directional language. Narrative intelligence tracks how stories evolve, connect and propagate across markets. For macro and commodities, narrative context is often more useful than a simple positive or negative score.
Teams should use point-in-time historical data, preserve original timestamps, understand revision handling and confirm that historical signals match what would have been available live at the time.
Permutable provides source-traceable market intelligence across macro, commodities, FX and geopolitical risk. The platform is designed to support institutional research, monitoring and production workflows through explainable signals and API-based delivery.

Analysis
15 Jul 2026
The Price of Passage: How Geopolitical Sentiment Led the Repricing of Gulf Crude-Flow Risk
Read more >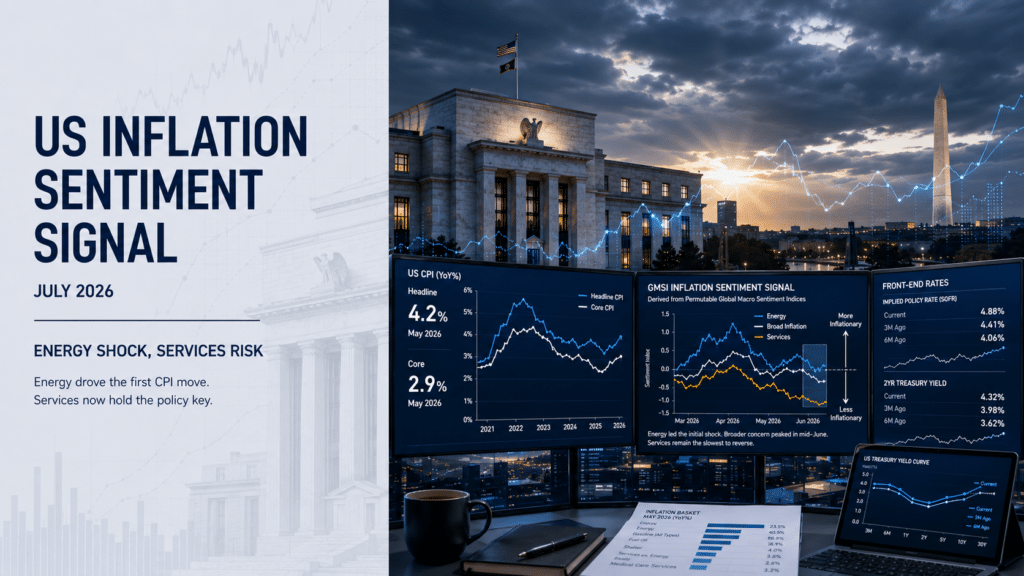
Analysis
08 Jul 2026
US inflation sentiment signal shows shift from energy shock to sticky services risk
Read more >
Analysis
07 Jul 2026
Testing GMSI US monetary policy sentiment as a short-end rates signal
Read more >